![[新機能] Amazon SageMaker Lakehouse 統合アクセス制御が Amazon Athena フェデレーテッドクエリ(プレビュー)で利用可能になったので試してみた #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3aqf4zA8eWdIL3CoGscPpm/224083826f6e4dd7b971c4967b706ad8/reinvent-2024-try-jp.jpg?w=3840&fm=webp)
[新機能] Amazon SageMaker Lakehouse 統合アクセス制御が Amazon Athena フェデレーテッドクエリ(プレビュー)で利用可能になったので試してみた #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。先日のre:Invent2024で発表された Amazon SageMaker Lakehouseの「データカタログとアクセス制御の統合」が、Amazon Athena フェデレーテッドクエリ(プレビュー)で利用可能になりました。先日のAmazon SageMaker LakehouseによるDynamoDBのZero-ETLに続き、本日はDynamoDBのZero-ETLへのAmazon Athena federated queriesを試してみます。
Amazon SageMaker Lakehouse 統合アクセス制御が Amazon Athena フェデレーテッドクエリで利用可能とは
大抵の人はわからないと思うので、段階的に解説します。
Amazon Athena フェデレーテッドクエリとは
Amazon Athena フェデレーテッドクエリとは、Amazon S3以外の様々なデータソースに対してSQLクエリを実行できる機能で、ユーザーは単一のAmazon AthenaのSQLクエリを使用して、オンプレミスやクラウド上のデータソースにまたがるデータ分析が可能になります。
下記の例では、Amazon Athena から Google BigQueryのテーブルに Amazon Athena のクエリが実行できる機能、「Amazon Athena フェデレーテッドクエリ」を紹介しています。
統合アクセス制御とは
Amazon SageMaker Lakehouseの統合アクセス制御とは、さらにデータカタログとアクセス制御の統合の2つを意味します。
データカタログ
Amazon SageMaker Lakehouseは、接続されたデータソースの情報(テーブル、カラムなど)がAWS Glue Data Catalogに自動登録する自動カタログ機能があります。
アクセス制御
Amazon SageMaker Lakehouseは、データソースの情報(テーブル、カラムなど)をGlue Data Catalogに登録することで、Lake Formationを使用して、細粒度(fine-grained)のアクセス制御ポリシーを定義し、アクセス制御できるようになります。
つまり、
(Amazon SageMaker Lakehouseの)統合アクセス制御とは、様々なデータソースへの接続、データの発見、そして権限管理を一元化する機能です。この機能により、Amazon Athenaのフェデレーテッドクエリを通じて、異なるデータソースに対する統一されたアクセスと分析が可能になります。
特長
統一されたメタデータストア
AWS Glue Data Catalogを使用して、すべてのデータソースのメタデータを一元管理します。
シンプルな接続管理
データソースへの接続を一度設定すれば、繰り返し利用できます。
自動カタログ化
接続されたデータソースのデータベースとテーブルが自動的にカタログ化されます。
細粒度(fine-grained)のアクセス制御
AWS Lake Formationを通じて、詳細なアクセス制御ポリシーを定義できます。
データの整合性維持
データは元の場所に保持されるため、コストのかかるデータ転送や複製が不要です。
この機能の仕組み
データソース接続の作成
SageMaker Unified Studioから、様々なデータソースへの接続を設定します。
自動カタログ化
データソースへの接続を設定すると、接続されたデータソースの情報がAWS Glue Data Catalogに自動登録されます。
権限設定
AWS Lake Formationを使用して、細粒度(fine-grained)のアクセス制御ポリシーを定義します。
データアクセス
設定された権限に基づき、ユーザーはAthenaを通じてデータにアクセス(クエリ)、分析を行います。
Amazon SageMaker Lakehouse の Amazon Athena フェデレーテッドクエリ を試す
Amazon SageMaker Lakehouse の Amazon Athena フェデレーテッドクエリ は、本日時点ではプレビューとなります。
データソースのDynamoDBテーブルを作成する
以下のコマンドを実行してテーブルを作成する。
aws dynamodb create-table \
--table-name customer_ddb \
--attribute-definitions \
AttributeName=cust_id,AttributeType=N \
AttributeName=zipcode,AttributeType=N \
--key-schema \
AttributeName=cust_id,KeyType=HASH \
AttributeName=zipcode,KeyType=RANGE \
--provisioned-throughput \
ReadCapacityUnits=5,WriteCapacityUnits=5 \
--table-class STANDARD
DynamoDB テーブルにデータを追加します。
aws dynamodb put-item \
--table-name customer_ddb \
--item \
'{"cust_id": {"N": "11"}, "zipcode": {"N": "2000"}, "mobile": {"N": "11113333"}}'
aws dynamodb put-item \
--table-name customer_ddb \
--item \
'{"cust_id": {"N": "12"}, "zipcode": {"N": "2000"}, "mobile": {"N": "22224444"}}'
aws dynamodb put-item \
--table-name customer_ddb \
--item \
'{"cust_id": {"N": "13"}, "zipcode": {"N": "3000"}, "mobile": {"N": "33335555"}}'
aws dynamodb put-item \
--table-name customer_ddb \
--item \
'{"cust_id": {"N": "14"}, "zipcode": {"N": "4000"}, "mobile": {"N": "55556666"}}'
DynamoDBのテーブルにリソースポリシーを設定します。
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": "*",
"Action": [
"dynamodb:Query",
"dynamodb:Scan",
"dynamodb:DescribeTable",
"dynamodb:PartiQLSelect"
],
"Resource": "arn:aws:dynamodb:ap-northeast-1:123456789012:table/customer_ddb",
"Condition": {
"ArnEquals": {
"aws:PrincipalArn": "arn:aws:iam::123456789012:role/datazone_usr_role_d65eufnjqarnh5_666humgfxgqk2h"
}
}
}
SageMaker Unified Studioにアクセス
SageMaker Unified Studioにアクセスし、プロジェクトを選択します。プロジェクトをまだ作成していない方は、以下のブログを参考にプロジェクトを作成してください。
左側のナビゲーションペインから「Overview」-「データ」を選んで、プラスボタンを押します。
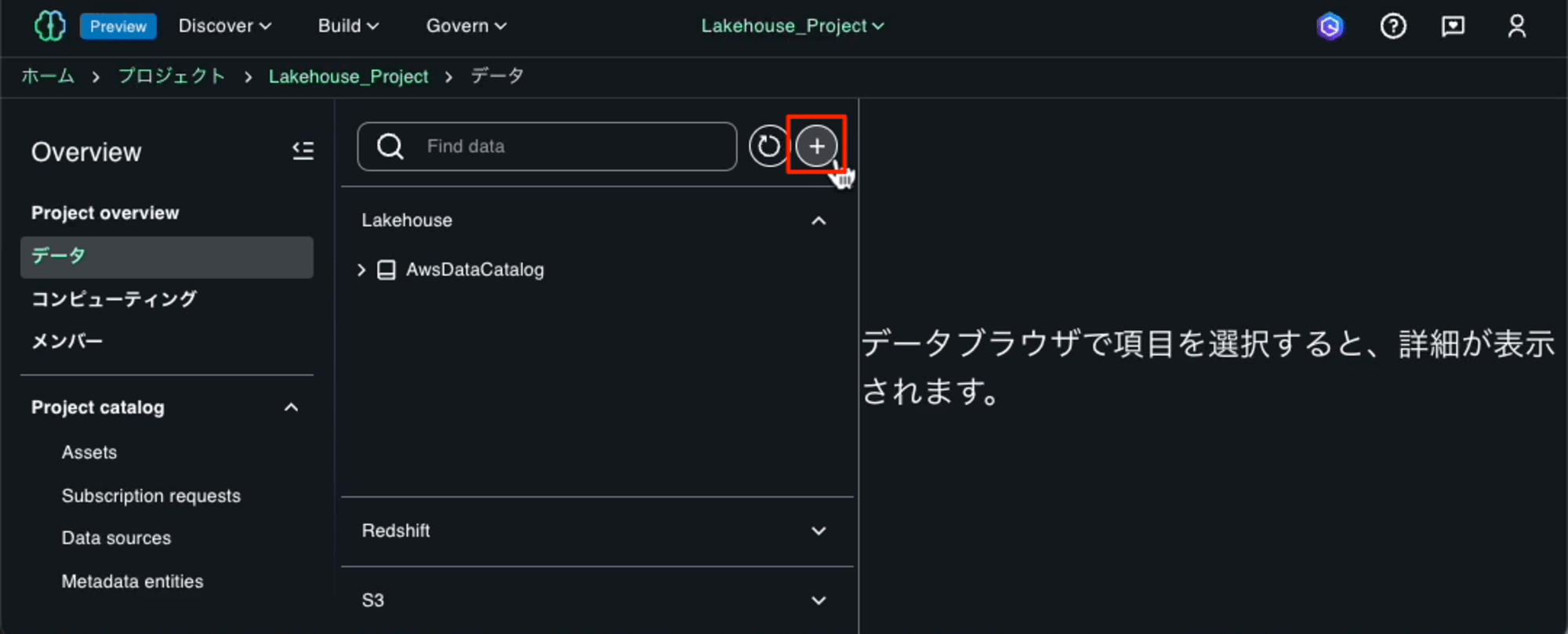
「Add connection」を選択します。
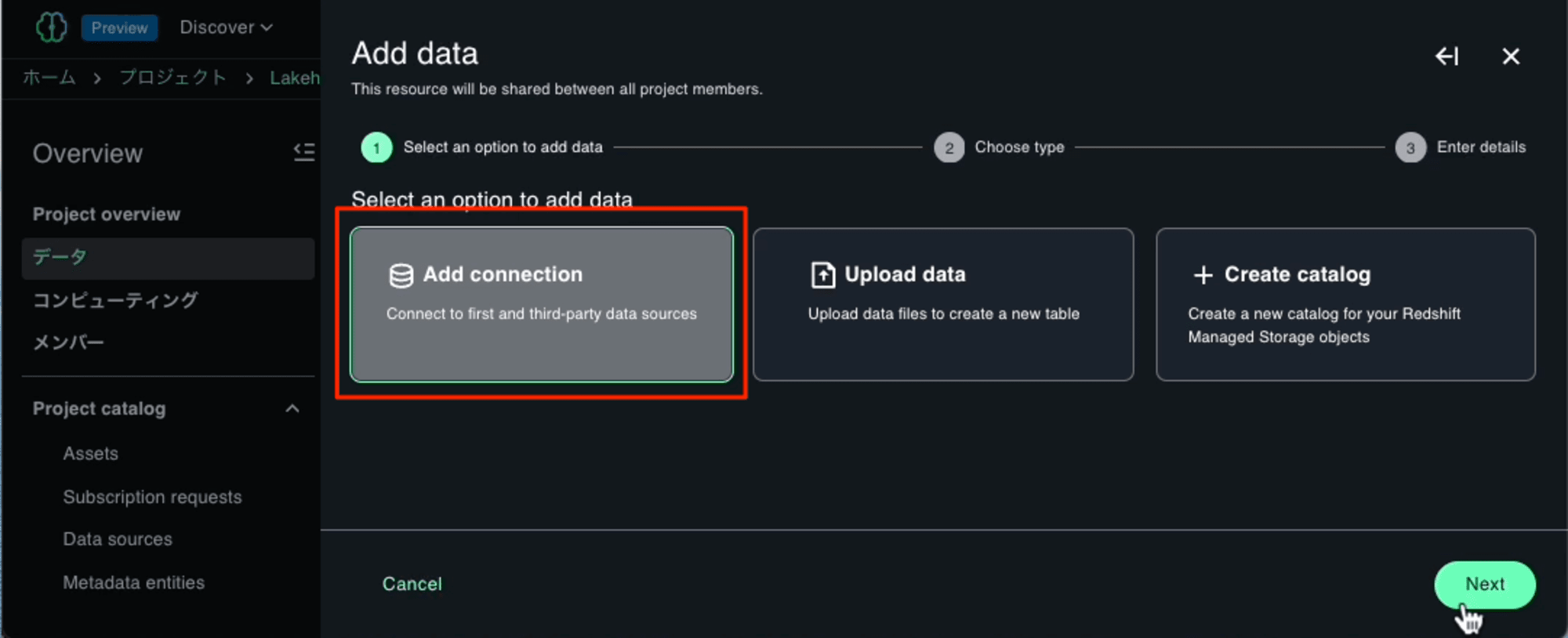
目的のデータソース「Amazon DynamoDB」を選択します。
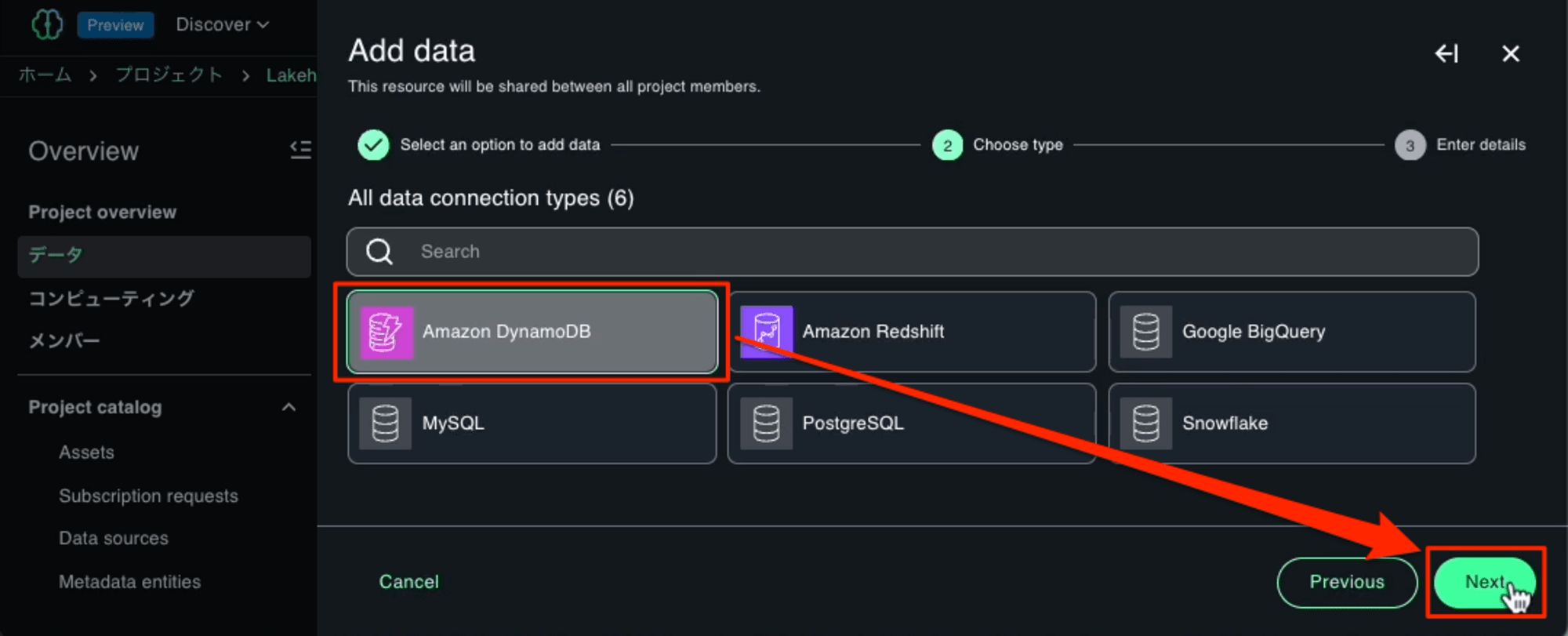
Nameに今回は「dynamodb」を入力しました。ここで入力したNameとはCatalogの名前になります。
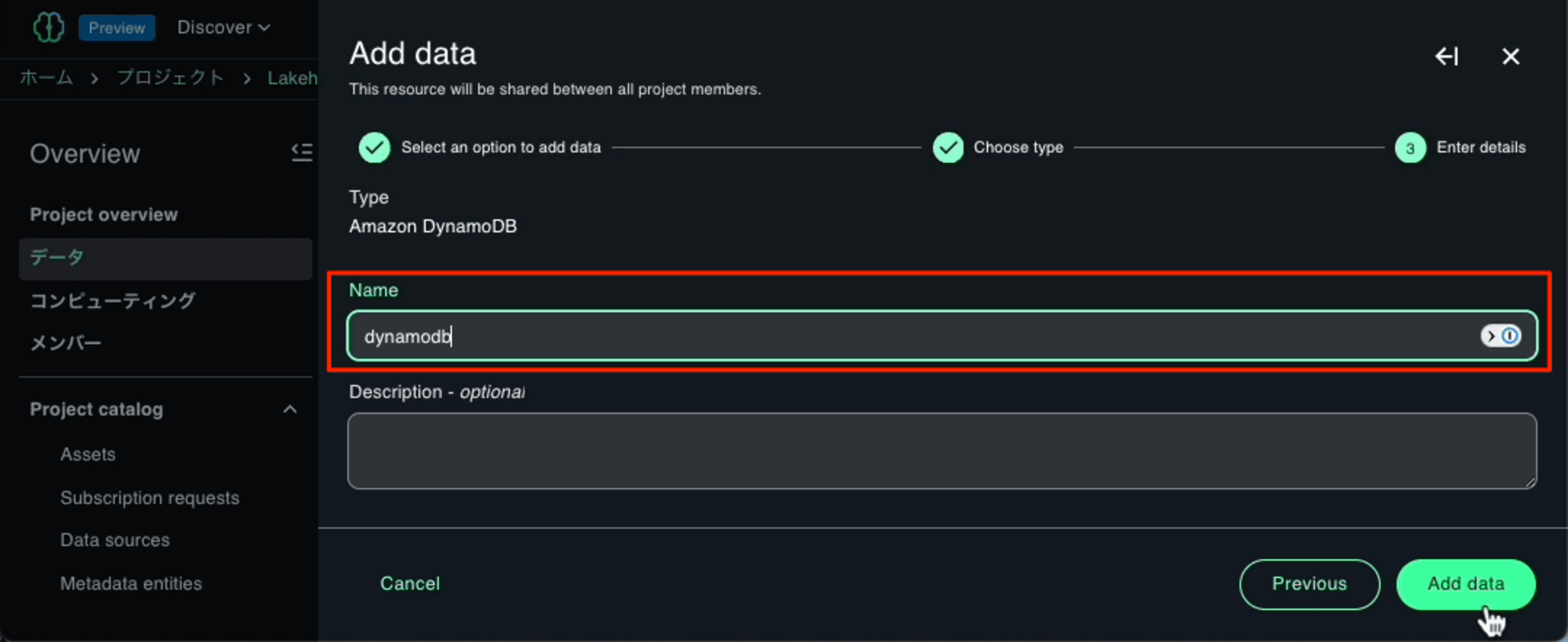
[Add data]を押すと、接続の作成が開始します。
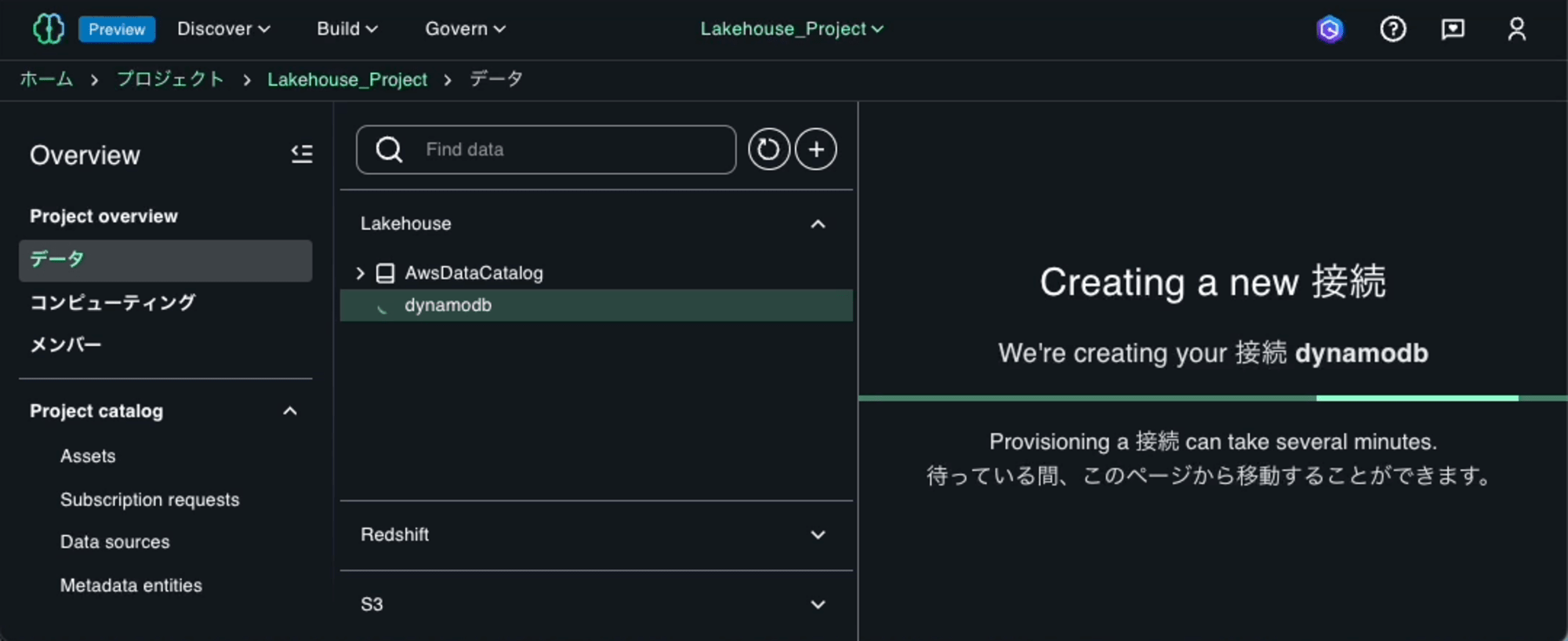
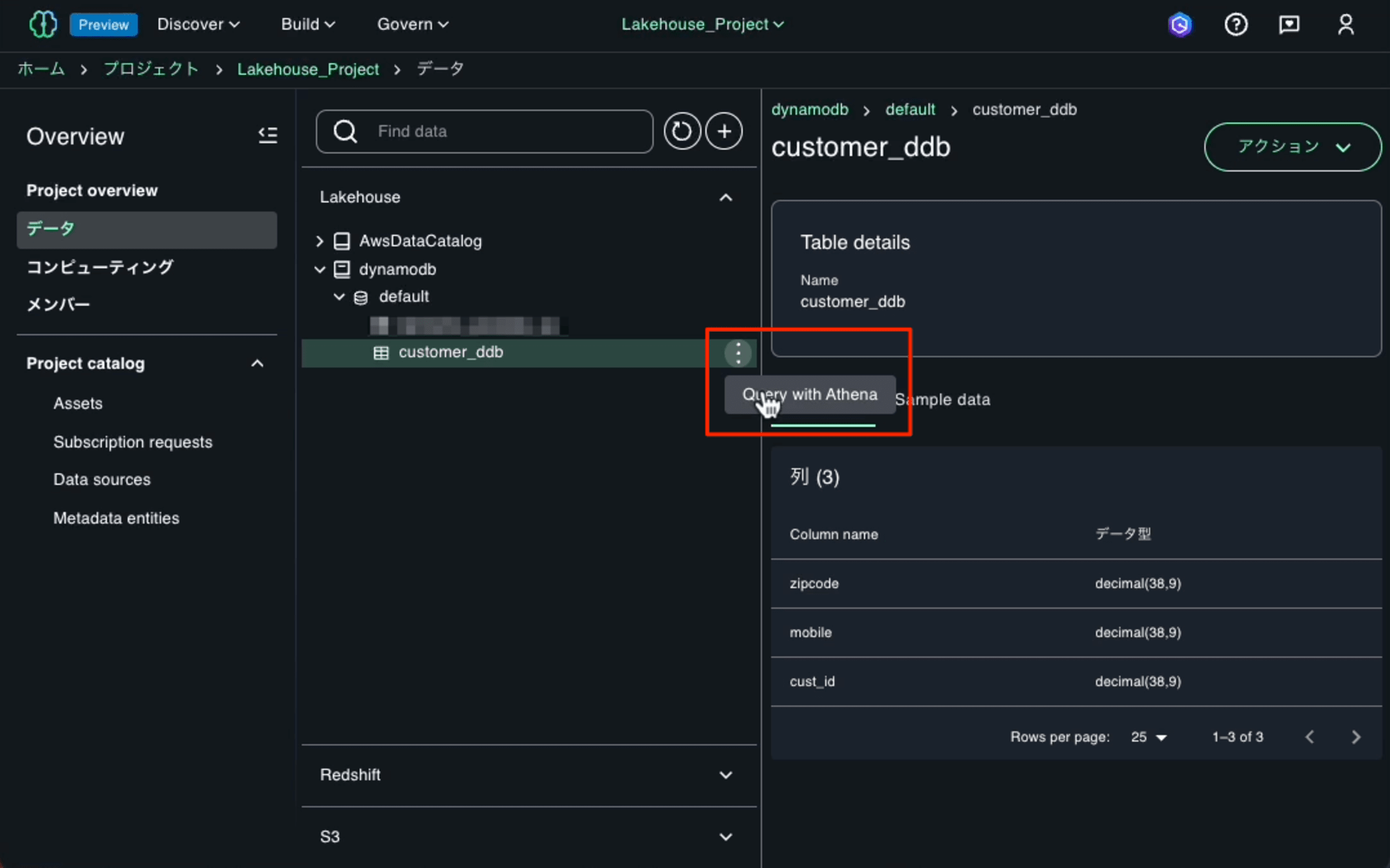
接続作成が完了すると「dynamodb」というCatalogが追加されます。その下のcustomer_ddbテーブルがあることが確認できます。テーブル名の右の[⋮]ボタンを押して「Query with Athena」オプションを使用して、設定したデータソースに対してクエリを実行し、アクセス制御が正しく機能していることを確認します。
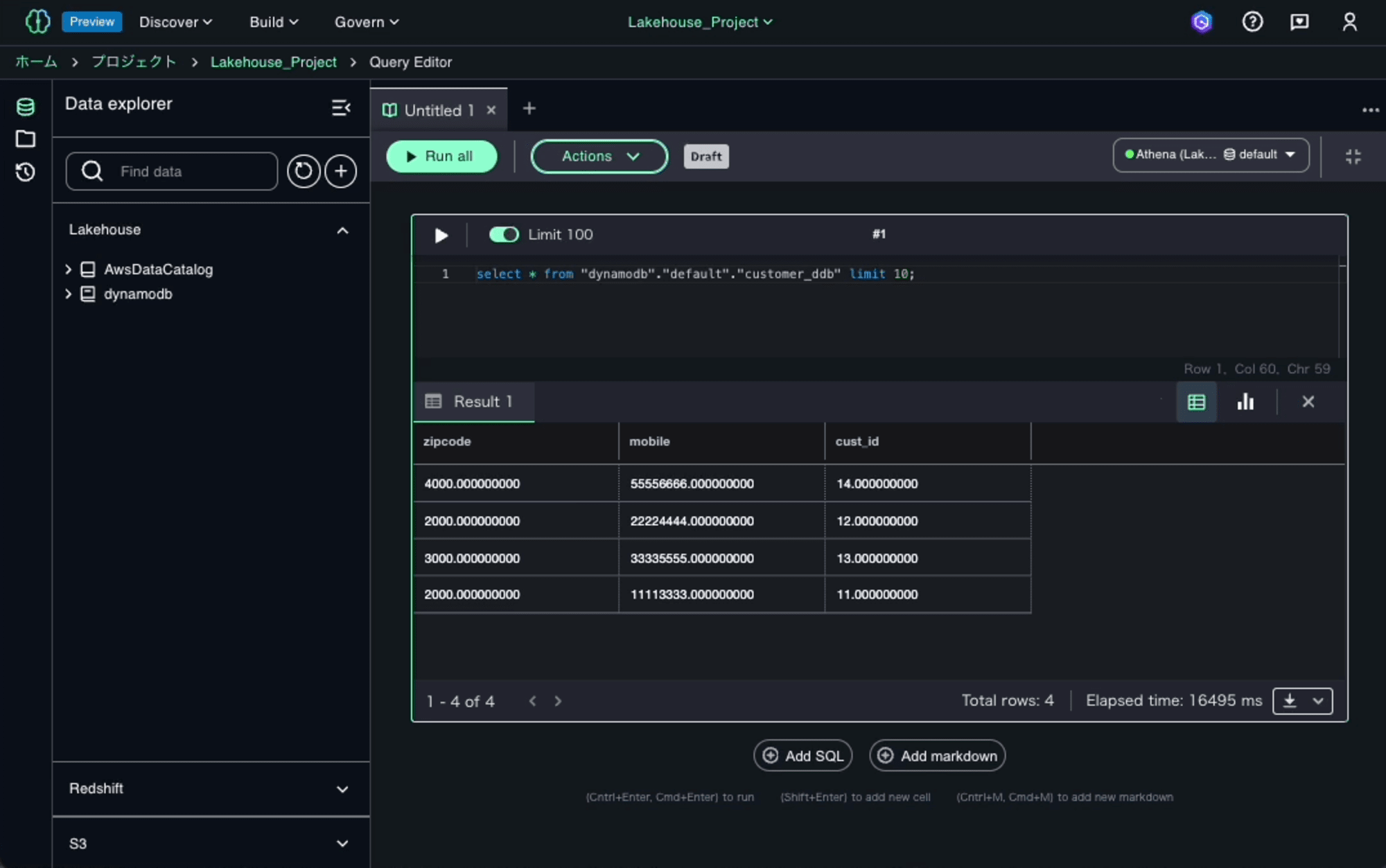
クエリが表示されると、直ちにクエリが実行して、クエリの結果が参照できます。実際に表示されるまでに10秒ほどの時間がかかりました。
最後に
Amazon SageMaker Lakehouseの統合アクセス制御がAmazon Athenaフェデレーテッドクエリで利用可能になったことで、様々なデータソースへの接続、データの発見、そして権限管理を一元化することで、組織のデータ操作の効率化とセキュリティガバナンスの強化を実現します。
AWS Glue Data Catalogを使用したメタデータの一元管理、シンプルな接続管理、自動カタログ化、そしてAWS Lake Formationを通じた細粒度のアクセス制御など、多くの利点を提供します。これにより、データの整合性を維持しつつ、コストのかかるデータ転送や複製を避けることができます。さらに、この機能はAI/ML開発の加速にも貢献し、データ駆動型ビジネスにとって不可欠なツールとなります。
合わせて読みたい










